機器學習與編程 軟件開發中的根本差異
在軟件開發領域,機器學習和傳統編程雖然都涉及代碼編寫,但它們的核心思想和方法存在顯著區別。
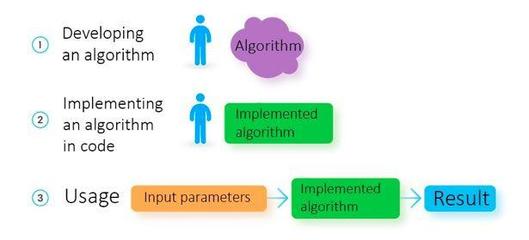
傳統編程依賴于明確的邏輯規則和指令。開發者需要預先定義輸入與輸出之間的關系,編寫詳細的算法和條件判斷。例如,開發一個計算器應用時,程序員必須明確指定加法、減法等運算的步驟。系統的行為完全由代碼邏輯決定,結果可預測且穩定。
相比之下,機器學習不依賴人工編寫的規則,而是通過數據驅動的方式自動學習模式。開發者提供大量數據(如用戶行為記錄或圖像樣本)和期望的輸出,機器學習模型會自行發現數據中的規律,并生成預測或決策。例如,開發一個垃圾郵件過濾器時,無需手動定義垃圾郵件的特征;模型會從標記的郵件數據中學習區分垃圾郵件與正常郵件。
二者的最大區別在于問題解決范式:傳統編程是“規則驅動”的,強調精確控制;而機器學習是“數據驅動”的,注重從經驗中歸納。在軟件開發中,傳統編程適用于邏輯明確、規則固定的任務(如操作系統或數據庫管理),而機器學習更適合處理復雜、模糊或動態的問題(如圖像識別或自然語言處理)。隨著人工智能的普及,許多現代軟件項目結合了二者,以兼顧效率與智能。
如若轉載,請注明出處:http://m.senz.org.cn/product/692.html
更新時間:2026-01-11 21:59:56